Clustering and Contingency Tables
Let X be a set of N data points {x1, x2, x3, ..., xN}. Given two clusterings of X, namely A={A1, A2, A3, ..., AR} with R clusters and B={B1, B2, B3, ..., BC} with C clusters, the information on cluster overlap between A and B can be summarized in the form of a R×C contingency table (CT) as illustrated in Figure 1. Every element of X contributes to the cell of the corresponding clusters in both A and B.
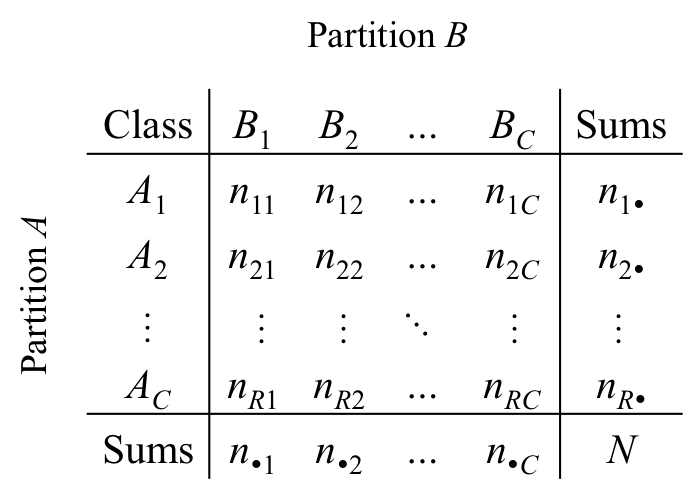
Figure 1: Contingency table. nij denotes the number of elements that are common to clusters Ai and Bj.
Focusing on the pairwise agreement, the information in the CT can be further condensed in a mismatch matrix:
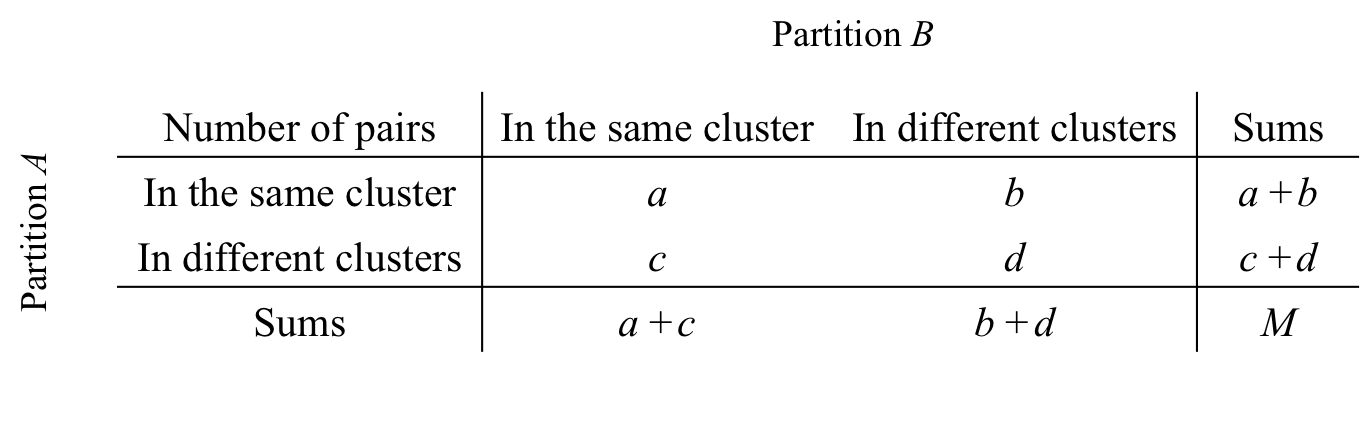
Figure 2: Mismatch Matrix. a, b, c and d represent counts of unique entity pairs.
Explicit formulae for calculating a, b, c and d in the mismatch matrix can be constructed using entries in the CT (Hubert & Arabie, 1985):

